错误
1、使用 urllib 模块的 request.urlopen 报错
简单的爬虫
1 | #usr/bin/python |
报错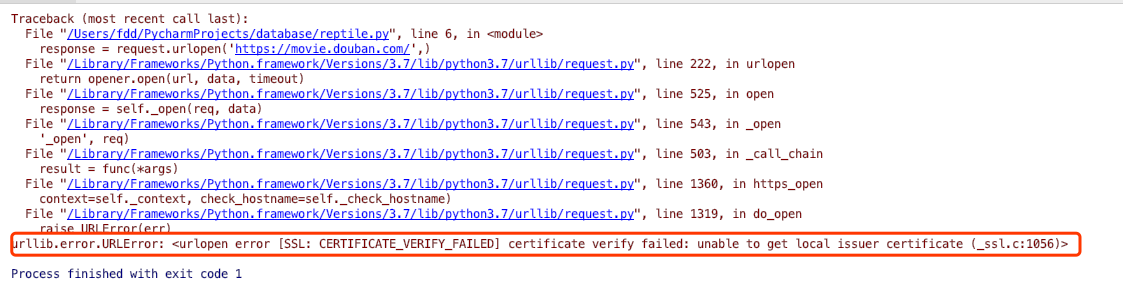
mac python 3.7
解决
Mac 二进制版本忽略了对 SSL 证书的验证
手动 ssl 证书验证
1 |
|
爬虫实例
1 | from urllib import request |

错误
简单的爬虫
1 | #usr/bin/python |
报错
mac python 3.7
Mac 二进制版本忽略了对 SSL 证书的验证
手动 ssl 证书验证
1 |
|
1 | from urllib import request |